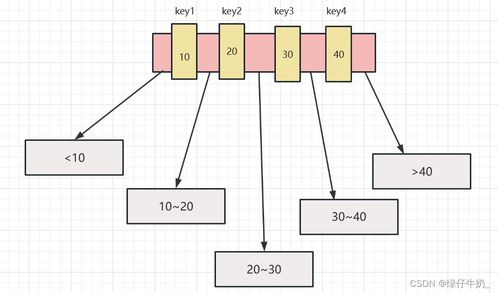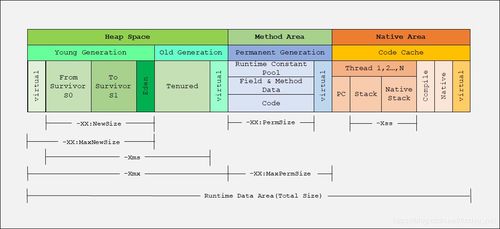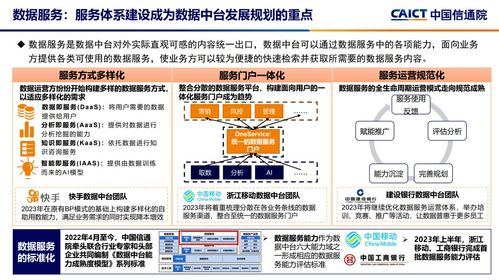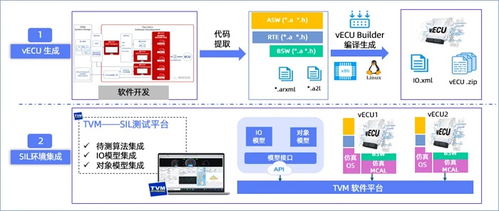
HDFS(Hadoop分布式文件系统)作为大数据生态系统的核心组件,为海量数据提供了可靠的存储基础,并高效支撑起数据处理流程。它通过分布式架构,将数据分散存储在多台机器上,实现高吞吐量的数据访问和强大的容错能力。
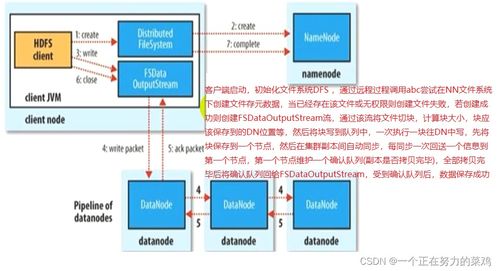
在数据存储方面,HDFS采用主从架构,包括NameNode和DataNode。NameNode负责管理文件系统的元数据,而DataNode则存储实际的数据块。这种设计不仅支持PB级数据的存储,还通过数据副本机制确保数据的安全性,即使部分节点发生故障,系统仍能正常运行。
对于数据处理,HDFS与MapReduce、Spark等计算框架紧密集成。数据可以本地化处理,减少网络传输开销,提升处理效率。HDFS支持流式数据访问,适合批处理和分析任务,广泛应用于日志存储、数据仓库和机器学习等场景。
HDFS不仅是一个高效的数据存储解决方案,更是数据处理生态中不可或缺的支撑服务,为企业和研究机构提供了稳定、可扩展的大数据基础。